Making a Gopherhole and Phlog
Jan 31, 2021
[ #gopher #100daystooffload ]
Contents
But Why?
The obvious questions is why make a Gopherhole (what gopher sites are called) when all the action is on the World Wide Web over html and http? Didn’t those protocols win the Internet two decades ago? I didn’t really think much about Gopher until I started reading more about the newer Gemini protocol on my foray into Mastodon last week and figuratively went “down” the Gopherhole.

I was suprised to find not only a flourishing community, but was drawn to the simplicity of the protocol and creating for it. No more thinking about CSS oddities, having to learn whole web stacks with the latest-and-greatest toolsets. Most of what Gopher is now is the same as it was in the early 90s and it’s something you can easily start learning about and doing without sinking a lot of time and effort just to get started. It reminds of learning Latin, even though it’s a dead language, it’s still useful and it will never change. It also has the advantages of being almost entirely text based and there’s no tracking, cookies, or any of the risks and privacy concerns associated with the modern web.
For a much more in-depth look on modern Gopher, I recommend reading Burrowing A Gopher Hole.
Start Burrowing
The first thing I needed to to was figure out how to host a Gopherhole. I could run it myself locally, and was thinking of re-purposing one of my numerous raspberrypis to self-host it over port 70. I even got as far as trying to make a Dockerfile to run gophernicus in a container and maybe even get it to run in Kubernetes! I quickly realized this was missing the point of slowing down and focusing on the simplicity that intially drew me in the first place and scrapped this idea.
While browsing Gemini capsules (the term for Gemini sites), I came across the PubNix RawText.club, whose mission fit with the themes of simplicity and do-it-yourself while offering some basic hosting services for gopher, gemini, and web.
RTC is a non-profit, do-it-yourself social network that uses a smaller, simpler, user-built toolkit. We are proudly the polar opposite of the big, exploitative, corporate-owned social media mega-sites. Not cool. Not easy. Not big. rawtext.club is what you make it. The point is that you can do a LOT using very minimal resources by stringing together command line tricks on a Linux system.
I pondered joining for a few days to make sure I would stick with the commitment and didn’t want to join and then lose interest a few weeks later. Even though RTC is a “slow” social network, I wanted to actively particpate in the community and not just be passive and looking for a free handout. Eventually I sent an invite request and was extended a membership. The first few days I spent checking out RTC from the cli; creating a prescense and reading the man pages for the local tools (which are excellent).
Finally I started adding things in ~ecliptik/public_gopher and got to work on making a gohperhole. Creating a gopherhole has been well covered by others in other blog posts, which I heavily referenced when making the site,
On RTC, home directories are world readable, so I poked around in some more well-known users public_gopher dirs and saw how their gopherholes were setup. I used the gopher browser Bombadillo as my main tool to view Gopherspace, and coincidentally Lagrange, the browser I was using to browse Gemini, also supported gopher and would use it occasionally as a GUI view.
The resulting gopherhole was relatively simple,
[ecliptik@rawtext public_gopher]$ tree .
.
├── about.txt -> ../.who-is
├── gophermap
└── phlog
1 directory, 2 files
The about page is a symlink to my ~/.who-is (which is used on RTC as a profile), a link to the Phlog dir, a web link to the www page, and a link back to the RTC gopherhole. The gophermap for this was simple.
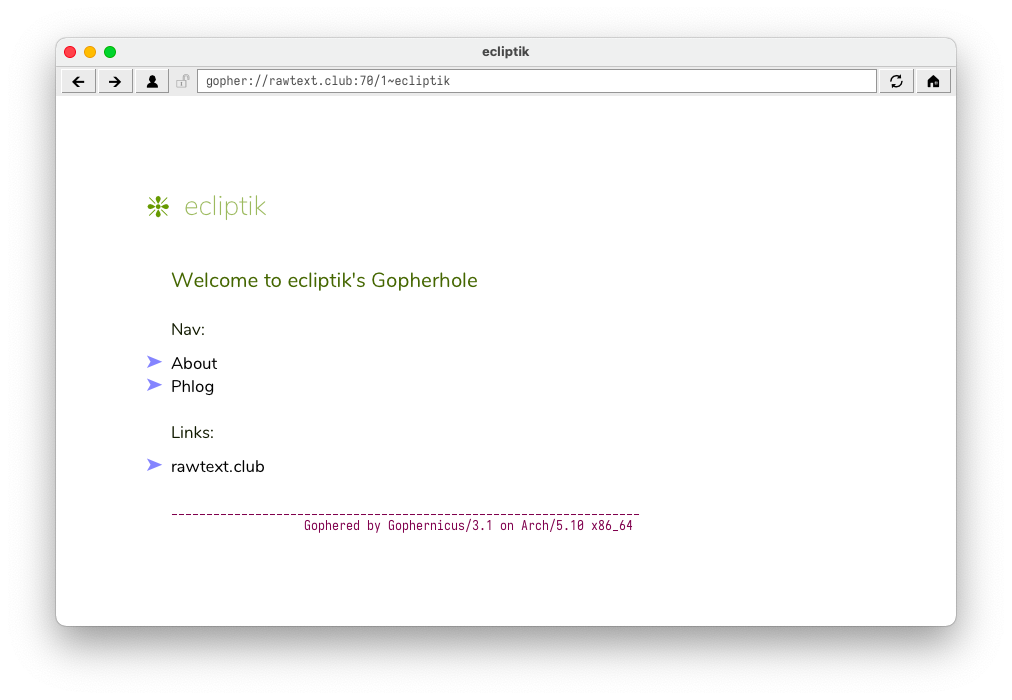
Welcome to ecliptik's Gopherhole
Nav:
0About about.txt
1Phlog ./phlog
Links:
hecliptik.com URL:https://www.ecliptik.com
1rawtext.club / rawtext.club 70
The most difficulty I had was getting the link identifiers and tabs in the correct places.
Adding these files made the site live at gopher://rawtext.club:70/1~ecliptik. If you don’t have a gopher browser installed it’s viewable through a gopher proxy from Floodgap.
Welcome to ecliptik's Gopherhole
Nav:
TXT [1] About
MAP [2] Phlog
Links:
HTM [3] ecliptik.com
MAP [4] rawtext.club
___________________________________________________________________
Gophered by Gophernicus/3.1 on Arch/5.10 x86_64
Phlog
After getting the basic site up I wanted to update it frequently with a Phlog, which is the gopher equivalent of a Blog. Since I already have this blog with Jekyll and uses markdown for posts, I thought I might as well mirror these posts to the Phlog. I also decided to only do the pure markdown posts, as some of the older posts on the blog were converted from my old blogger site and are HTML. Having to convert all of those to markdown or writing scripts to also convert HTML was a bit too much for this project.
A few others have already done this, as referenced above for Jekyll and Hugo already, but I wanted to do my own take on it. Originally I wrote a script that would convert a post to a gophermap, converting the links to blocks, identifying what type they were and creating item links.
#!/bin/bash
#Convert a jekyll markdown post to a gophermap
#Will create a sub-directory with the name of the post and a gophermap
#converted to 70 columns with links. Tries to do basic http or gopher
#linking. May not work well, but works well enough.
# usage: ./md2gophermap.sh ../_posts/post-to-convert.md
#Know Bugs
#Pandoc does not wrap code blocks to the columns length and will get cut
#off when rendered in the gophermap.
#see: https://github.com/jgm/pandoc/issues/4302#issuecomment-360669013
#Take input and craft output file and directory vars for use later on
input=$1
output=`basename ${input}`
outdir=`basename -s .md ${output}`
echo "converting ${input}"
pandoc --from markdown --to markdown --reference-links --reference-location=block --columns=70 -o ${output} ${input}
#Do some IFS changes in order to properly parse individual lines after conversion
IFSORIG=${IFS}
IFS="
"
#Create gophermap
##HTML link syntax
#hecliptik.com URL:https://www.ecliptik.com
##Gopher link syntax
#1rawtext.club / rawtext.club 70
#Go through the file line-by-line looking for http or gopher linkes and convert
for line in `cat ${output}`; do
IFS=${IFSORIG}
if echo "${line}" | egrep -e "^.+\[.+\]:.+" >/dev/null; then
case ${line} in
*http*)
itemname=`echo ${line} |sed -r 's/\[(.*)\]/\1/' | awk -F: {'print $1'} |xargs`
itemlink=`echo ${line} |awk -F] {'print $2'} | sed -e "s%:\ %%"`
item="h${itemname}\tURL:${itemlink}"
;;
*gopher*)
itemname=`echo ${line} |sed -r 's/\[(.*)\]/\1/' | awk -F: {'print $1'} |xargs`
itemserver=`echo ${line} |awk -F/ {'print $3'} | awk -F: {'print $1'}`
itemlink=`echo ${line} |awk -F/ {'print $4'}`
item="1${itemname}\t/${itemlink}\t${itemserver}\t70"
esac
#Set IFS to new line in order to remove leading spaces
IFS="
"
#Escape all special chars so they're replaced in sed
linemung=$(echo ${line} | sed -e 's`[][\\/.*^$]`\\&`g')
itemmung=$(echo ${item} | sed -e 's`[][\\/.*^$]`\\&`g')
#Replace markdown blocks with gophermap
sed -i -e "s/${linemung}/${itemmung}/" ${output}
sed -i -e "s/\\\t/\t/g" ${output}
fi
done
#Make the subdirectory
mkdir -p ${outdir}
#Use the top of the original Markdown file to create a basic header
head -6 ${input} | grep -v "layout" | grep -v "category" > ${outdir}/gophermap
echo "" >> ${outdir}/gophermap
cat ${output} >> ${outdir}/gophermap
#Convert --- lines to underscore
sed -i -E "s/^--.+$/$(printf '%.0s_' {0..69})/g" ${outdir}/gophermap
sed -i -E "s/^==.+$/$(printf '%.0s_' {0..69})/g" ${outdir}/gophermap
#Remove the pandoc output file to clean up
rm -fr ${output}
This worked out well, where a gophermap for each post under _posts was formatted properly into their own directories, wrapping was done, and the item links worked. However it just looked sort of off, and there was an issue where code blocks would not be wrapped by pandoc.
I decided then to just convert them to plaintext and not do a full gophermap, which preserved the formatting, wrapped text blocks more accurately, and just looked better in general. Most of the links in the posts are http anyway, so if they were followed they’d open in a web browser anyway.
#!/bin/bash
#Convert a jekyll markdown post to plaintext suitable for gopher,
#converted to 70 columns
#usage: ./md2gopher.sh ../_posts/post-to-convert.md
#Take input and craft output file and directory vars for use later on
input=$1
outdir="_posts"
output="${outdir}/`basename -s .md ${input}`.txt"
mkdir -p ${outdir}
echo "converting ${input} to ${output}"
pandoc --from markdown --to plain --reference-links --reference-location=block --columns=70 -o ${output}.tmp ${input}
#Use the top of the original Markdown file to create a basic header
head -6 ${input} | grep -v "layout" | grep -v "category" > ${output}
echo "" >> ${output}
cat ${output}.tmp >> ${output}
rm -fr ${output}.tmp
These plaintext posts rendered much nicer and I was happy with how they turned out.
One final step was automatically generating a Phlog index of posts. The post Making a Gopherhole that I used when making my own Gopherhole had a script on taking the last 10 posts and generating a gophermap of them. I took this script and modified it some to include some things like a basic layout template.
#!/bin/bash
#Create gophermap of last 10 posts
#Originally from: https://johngodlee.github.io/2019/11/20/gopher.html
#Use layout file for header on gophermap
cat _layouts/phlog > gophermap
all=(_posts/*.txt)
# Reverse order of posts array
for (( i=${#all[@]}-1; i>=0; i-- )); do
rev_all[${#rev_all[@]}]=${all[i]}
done
# Get 10 most recent posts
recent="${rev_all[@]:0:10}"
# Add recent post links to gophermap
for i in $recent; do
line=$(head -n 4 $i | grep -i "title:" | awk -F: {'print $2'} | xargs)
printf "0$line\t$i\n" >> gophermap
done
#Append footer with html link
echo "" >> gophermap
printf '%.0s_' {0..69} >> gophermap
echo "" >> gophermap
echo "hecliptik.com URL:https://www.ecliptik.com" >> gophermap
The gophermap created while not fancy works well in displaying the latest 10 posts,
ecliptik's phlog
___________________________________________________________________
These posts are mirrored from https://www.ecliptik.com
___________________________________________________________________
Latest 10 posts
___________________________________________________________________
TXT [1] One Week With Mastodon
TXT [2] ACI Connector for k8s on a Raspberry Pi Cluster
TXT [3] Raspberry Pi Kubernetes Cluster
TXT [4] Cross Building and Running Multi-Arch Docker Images
TXT [5] Automating Container Updates With Watchtower
TXT [6] Containerizing a Perl Script
TXT [7] Emulating ARM64 on Linux
TXT [8] Decompiling Interactive Fiction
TXT [9] Building a website with Github and Jekyll
TXT [10] Vim, rdesktop, external monitors, and X Forwarding on a Google CR-48
___________________________________________________________________
HTM [11] ecliptik.com
___________________________________________________________________
Gophered by Gophernicus/3.1 on Arch/5.10 x86_64
While writing these tools I initially was creating them on my laptop, putting them into a tarball, scping them to RTC and then untarring them. This added a lot of manual steps into the process, so I took the more modern workflow of checking the converted posts into git, cloning them to RTC, the symlinking them from the gopherhole. This way after writing a post (such as this one), I’ll run the scripts, push and then pull on RTC and my phlog will be updated along with the WWW site.
These tools and usage are describe more in their README.md
Conclusions
While gopher didn’t win against the web in the early 90’s, it’s sense of simplicity really shines in todays modern and complex Internet. I’ve already found a lot of interesting content while browsing gopherspace that I wouldn’t find on the WWW and there is much more a sense of community, similar to what the web was like in the early days before modern social networking.