Bookmarking and Creating a Local Internet Archive
Jan 04, 2022
[ #hack #bookmarks #archiving ]
Contents
Intro
While I’m a heavy user of RSS with Newsblur, I’ve never had a coherent bookmarking solution. Last week I finally setup a proper bookmark manager, and as a bonus, archived bookmarked pages locally in my own personal Internet Archive.
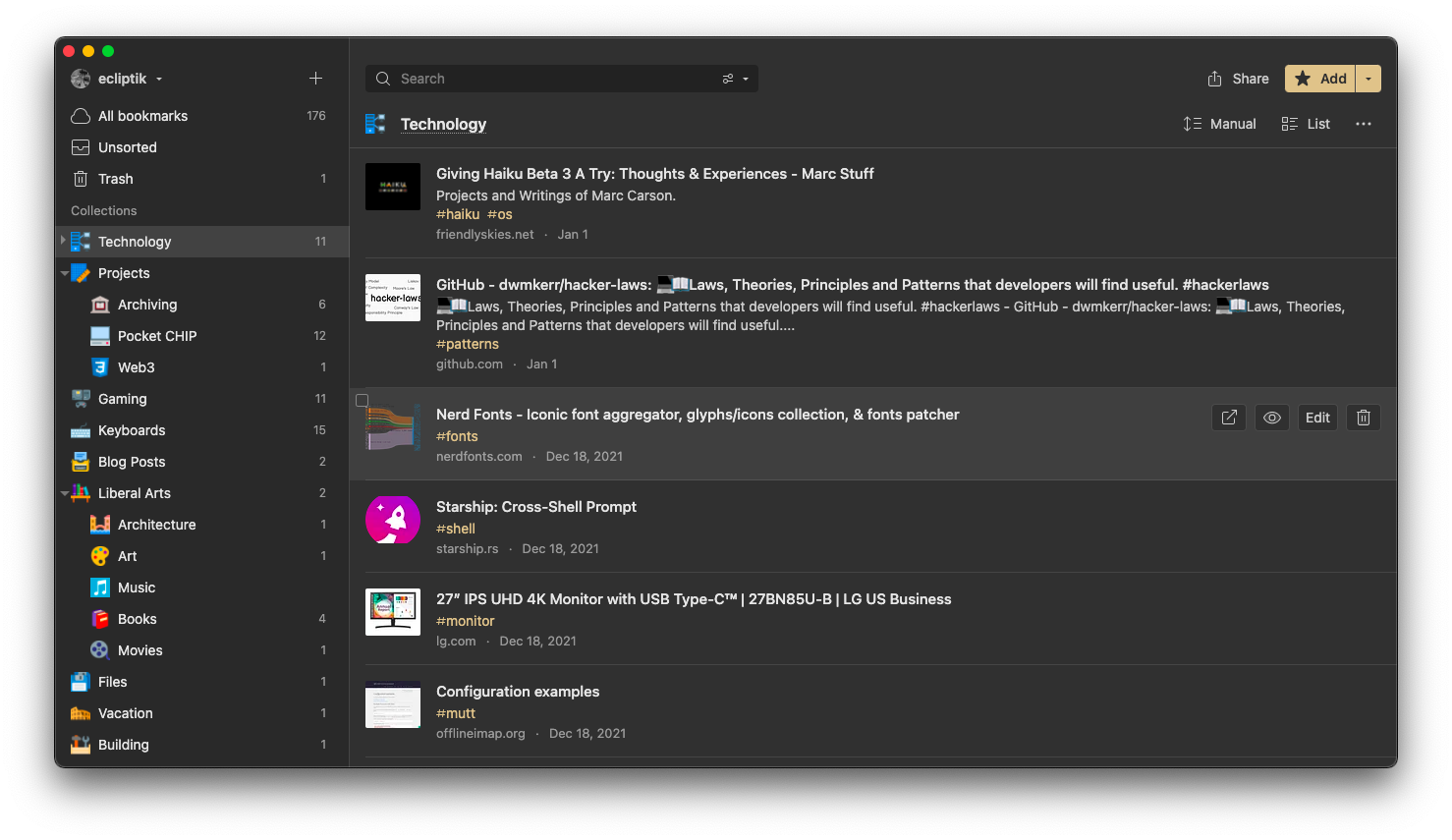
Bookmarking With Raindrop.io
A long time ago I was a user of del.icio.us, and first looked into using Pinboard for bookmarking. While Pinboard had most of the features I wanted - it lacked a native mobile app. I looked into other alternatives, and I ended up subscribing to Raindrop.io after using it for a few days on a trial basis.
Raindrop.io had all the features I was looking for,
- Free and Paid Subscription models
- Mobile App
- Permanent Copies
- Full text search
- Tagging
- Dropbox sync
Using the apps or browser extensions is seamless, making it easy to save bookmarks no matter what device or browser I’m using. I also imported all of my Firefox bookmarks which required some cleaning up, but gave a good impression of how the tool looks with content. I’m still experimenting with categories and tagging, but overall there’s some order to the chaos, and with tags and full text search I can quickly find sites without having to resort to a search engine.
I also setup an IFTTT automation so whenever a page is bookmarked in Raindrop.io, it will add it to Saved Stories in Newsblur with the tags. While it’s not really that useful, it can act as a sort of backup if needed and maybe in the future Newsblur will add some feature that makes it more useful.
Archiving Locally with ArchiveBox
While researching bookmarking services, I stumbled across ArchiveBox, which can create a local Internet Archive of webpages, media, and other thing from the web. It can also import bookmarks, archiving them locally and sending them to archive.org.
This got me thinking, the Backup feature in Raindrop.io saves an Export.html to Dropbox. I could setup Dropboxy sync on my server and have a cronjob import every hour, syncing all new bookmarks from Raindrop.io into ArchiveBox automatically.
My first attempt at this was successful, but the Export.html backup is a <!DOCTYPE NETSCAPE-Bookmark-file-1> format, and while ArchiveBox can import it, it doesn’t do it all that well - creating archives of parts of pages, not applying tags, and just overall wasn’t very consistent.
I found that ArchiveBox can also import a json formatted file with a simple array schema with a url: and tags: fields, so I wrote a quick script to convert this Backup.html into an import.json and then import it into ArchiveBox using docker-compose. Putting this into an hourly cronjob then automatically imports any new bookmarks and archives them.
This script gets all bookmarked URLs and tags from Export.html and creates a import.json with a structure of,
import.json:
[
{ "url": "https://www.friendlyskies.net/notebook/giving-haiku-os-beta-3-a-try", "tags": "haiku,os" },
{ "url": "https://github.com/dwmkerr/hacker-laws", "tags": "patterns" },
...
{ "url": "https://www.benoakley.co.uk/tartan-asia-extreme", "tags": "korean,japanese,film,movies" },
{ "url": "https://drodio.com/creating-your-own-remote-workspace-for-under-5k/", "tags": "wfh,shed,backyard" }
]
raindrop-import.sh:
#!/bin/bash
#Imports bookmarks from Raindrop.io
#Backup file from Raindrop sync on Dropbox
exportfile="~/Dropbox/Apps/Raindrop.io/Export.html"
importfile="~/Dropbox/Apps/Raindrop.io/import.json"
count=0
delimiter=','
echo "[" > ${importfile}
#Cleanup import to only get raw links
for url in $(grep -io '<a href=['"'"'"][^"'"'"']*['"'"'"]' ${exportfile} | sed -e 's/^<a href=["'"'"']//i' -e 's/["'"'"']$//i'); do
tags=$(grep "A HREF=\"${url}\"" "${exportfile}" | grep -io 'tags=['"'"'"][^"'"'"']*['"'"'"]' | sed -e 's/^tags=["'"'"']//i' -e 's/["'"'"']$//i' | tr '\n' ',')
munged_tags=${tags%?}
echo "{ \"url\": \"${url}\", \"tags\": \"${munged_tags}\" }${delimiter}" >> ${importfile}
done
#Trim last , in file before finishing array to make it valid JSON
sed -i '$ s/.$//' ${importfile}
echo "]" >> ${importfile}
#Check that JSON is valid before importing
if jq -e . >/dev/null 2>&1 < "${importfile}"; then
echo "Successfully Parsed JSON from ${importfile}"
else
echo "Unsuccessfully Parsed JSON from ${importfile}"
exit 1
fi
#Import exportfile into archivebox using docker-compose
docker-compose -f ~/archivebox/docker-compose.yml run --rm archivebox add --parser json < ${importfile}
When imported, only these URLs are archived and the tags are applied properly, creating an complete archived copy of bookmarks saved in Raindrop.io.
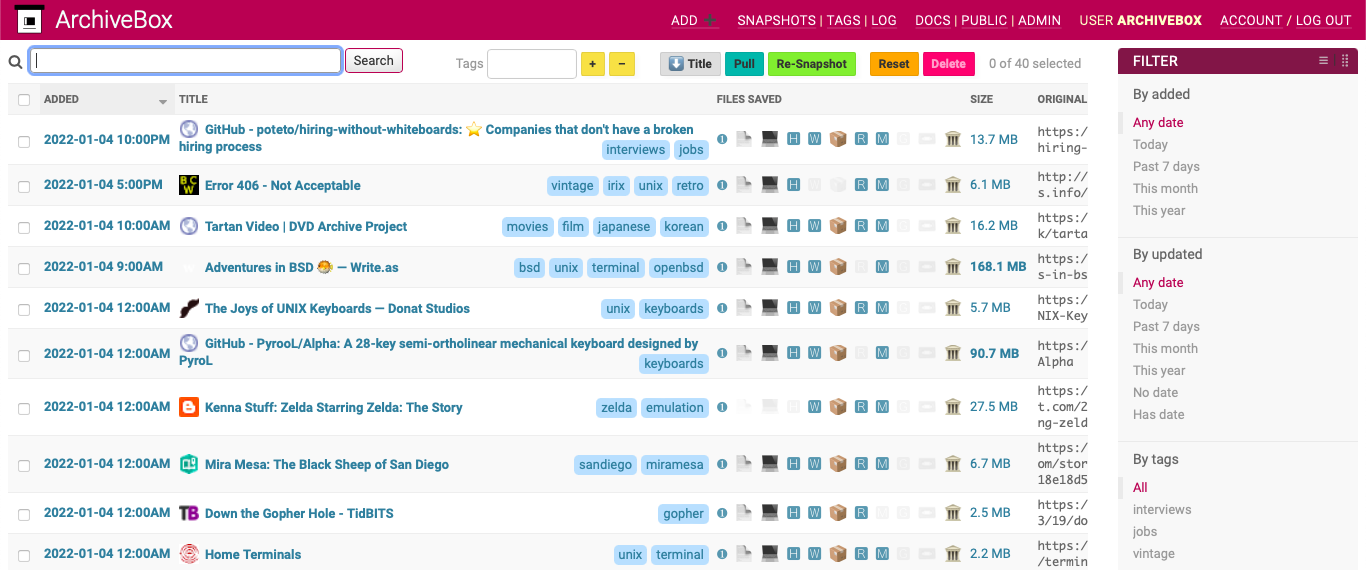
Since Raindrop.io has preview/live/archive views as well as fulltext search, I probably won’t use ArchiveBox frequently, but it’s good to have a local backup in multiple formats just-in-case. It also automatically sends the page to archive.org, so it’s another guarentee that it is archived somewhere in case the page disappears 10 years from now. By default it will also save a PDF file and text using Mercury and Readability which I may work on setting up to send to my Kindle for offline reading.
Conclusion
I now have a featureful bookmarking service that I can use almost anywhere, and have started making extensive use of it already. I wish I had setup something like this years ago, as there are many sites I’ve come across that I wish I could reference but completely forget how to find them using a search engine. Now can I not only quickly find them in my bookmark manager, but I also have my own local archive I can rely on in the future as well.